Cet article n’est pas comme les autres sur ce blog. D’habitude je parle en général à un public déjà technique. Là, j’écris pour tout le monde : si vous utilisez ChatGPT, Claude, Gemini ou Vibe de temps en temps sans rien y connaître, c’est exactement pour vous. Aucun jargon ne passera sans être expliqué. Promis.
Vous avez sûrement déjà tapé une question dans un assistant IA. Une recette, un mail à reformuler, une traduction. Et quand vous l’avez fait, vous avez utilisé le modèle proposé par défaut. Le plus souvent, il s’agit du plus récent et du plus puissant, parce que c’est celui que les fournisseurs d’IA mettent en avant.
C’est un réflexe parfaitement normal. C’est aussi, la plupart du temps, du gâchis.
Avant d’aller plus loin, soyons clairs sur l’esprit de cet article. Je ne viens pas vous dire s’il faut utiliser l’IA, ni pour quelles tâches : ce n’est pas mon rôle, et chacun a son avis sur la question. Je pars d’un constat tout simple : aujourd’hui, l’IA est massivement utilisée, au travail comme à la maison. Puisque c’est le cas, autant comprendre ce qui se passe derrière, ce que ça consomme réellement en ressources, pour faire ses propres choix en connaissance de cause. Mon but ici n’est pas de moraliser ni de vous pousser dans un sens ou dans l’autre, mais d’informer et de vulgariser. Rien de plus.
Le bouton que personne ne touche#
Commençons par un ordre de grandeur. D’après une étude de l’UNESCO menée avec l’University College London, une requête type à un assistant IA consomme environ 0,34 wattheure. C’est très peu : l’équivalent de quelques secondes d’une ampoule LED allumée. Pris isolément, ça ne mérite ni culpabilité ni panique.
Le problème, c’est l’addition. La même étude estime qu’un seul grand service d’IA totalise plus de 310 gigawattheures par an. Difficile de se représenter ce que ça veut dire, alors prenons une image bien française : un réacteur nucléaire de notre parc produit de l’ordre de 6 milliards de kWh par an. Ces 310 GWh, c’est donc à peu près 5 % de la production annuelle d’un réacteur, comme si on en dédiait un vingtième, qui tournerait jour et nuit toute l’année, rien que pour répondre aux questions d’un seul de ces services. (C’est un ordre de grandeur, pas une mesure au kWh près.) Quand des centaines de millions de personnes posent chacune des dizaines de questions par jour, les petits ruisseaux font de très grandes rivières.
Et voici le détail que presque personne ne remarque : dans la plupart de ces applications, il y a un petit menu déroulant (le sélecteur de modèle) qui permet de choisir avec quel « cerveau » l’IA va vous répondre. Un modèle léger, ou un modèle lourd. Ce bouton, quasiment personne ne l’ouvre.
C’est dommage, parce que c’est sans doute le geste de sobriété numérique le plus simple qui existe. Et il a un avantage que les gestes écologiques n’ont pas souvent : il ne demande aucun sacrifice. Choisir le bon modèle pour la bonne tâche, c’est à la fois plus rapide, moins cher et plus sobre. Les trois vont dans le même sens.
« Petit » modèle, « gros » modèle : c’est quoi la différence ?#
Imaginez que vous vouliez juste casser une noisette. Vous pouvez prendre un casse-noix, ou sortir la masse de chantier du garage. La masse y arrivera, bien sûr, mais c’est démesuré : elle est lourde à manier, plus longue à mettre en œuvre, et la noisette est cassée pareil (quand vous ne l’avez pas pulvérisée au passage).
Les modèles d’IA, c’est pareil. Un gros modèle (on dit aussi « modèle frontière », le haut de gamme) est une énorme machine entraînée pour gérer les tâches les plus difficiles : un raisonnement scientifique complexe, un problème de maths ardu, une analyse très fine. Un petit modèle (ou modèle « léger ») est une version plus compacte, plus rapide, qui consomme beaucoup moins, et qui s’en sort très bien pour tout ce qui est courant.
Deux mots de vocabulaire
On mesure la « taille » d’un modèle en paramètres : voyez-les comme le nombre de connexions dans un cerveau artificiel. Plus il y en a, plus le modèle est capable… et gourmand. Certains modèles ont aussi un mode « raisonnement » (parfois appelé « réflexion ») : au lieu de répondre du tac au tac, le modèle « réfléchit à voix haute » avant de répondre. Très utile pour un problème compliqué, mais on va voir que ça coûte cher.
Petite nuance importante : certains services choisissent automatiquement le modèle à votre place (ils « routent » votre question vers le bon cerveau). C’est pratique, mais opaque : vous ne savez pas ce qui a été utilisé. Le sélecteur manuel reste le seul geste que vous maîtrisez vraiment.
Remettons les idées à l’endroit (dans les deux sens)#
Sur le sujet « IA et écologie », on entend tout et son contraire. Essayons d’être justes, sans tomber dans un excès ni dans l’autre.
D’abord, dédramatisons. Une requête simple à une IA n’est pas la catastrophe écologique qu’on imagine parfois. Charles Duprat (ICOM’Provence) a publié en mars 2026 une analyse qui pose la question autrement : au lieu de regarder seulement le serveur, il mesure toute la chaîne, de votre première recherche jusqu’à la réponse finale. Surprise : poser une question à un assistant IA peut consommer moins d’énergie que la même recherche faite sur le web depuis un mobile : l’étude avance un rapport d’environ 5,4 fois en faveur de l’IA. La raison ? Une page web moderne pèse lourd (publicités, scripts, images : 2,5 Mo en moyenne), là où une réponse d’IA n’est que du texte. L’auteur a éprouvé la solidité de son calcul avec une simulation sur 10 000 scénarios : le résultat tient.
Autrement dit : utiliser une IA pour une question simple, ce n’est pas un péché écologique, en tout cas pas plus qu’une recherche Google. Respirez.
Maintenant, restons vigilants, parce qu’il y a deux pièges.
Le premier, c’est le mode raisonnement dont on parlait plus haut. Le faire « réfléchir » pour rien, c’est très coûteux : selon la même analyse, ces modes peuvent consommer 30 à 700 fois plus qu’une réponse directe. Activer le raisonnement pour demander une recette de pâtes, c’est ressortir la masse pour notre noisette… en prenant de l’élan en plus.
Le second piège porte un nom : le paradoxe de Jevons. L’idée est vieille de 150 ans et toujours vraie : quand une technologie devient plus efficace et plus facile à utiliser, on a tendance à l’utiliser beaucoup plus, au point d’annuler les économies réalisées. Les voitures consomment moins qu’avant, mais on roule davantage. Le micro-ondes chauffe une assiette pour bien moins cher que le four, sauf qu’on s’en sert dix fois par jour. L’IA suit le même chemin : plus elle est pratique, plus on la sollicite. Raison de plus pour que chaque sollicitation soit, individuellement, la plus sobre possible.
Les tâches où le petit modèle suffit largement#
Dans la pratique, pour l’immense majorité de ce qu’on demande à une IA, le petit modèle fait le travail aussi bien que le gros, en répondant plus vite. Voici les usages les plus courants, ceux que des millions de gens font chaque jour, pour lesquels il n’y a vraiment aucune raison de sortir la grosse machine.
Au quotidien :
- Reformuler ou adoucir un message : un mot un peu sec à faire passer, une demande délicate à tourner poliment.
- Traduire un texte courant : un mail, un message à l’hôte d’une location, un mode d’emploi.
- Résumer en clair : un courrier administratif plein de jargon, un article trop long, des conditions générales.
- Expliquer simplement un mot compliqué : un terme médical sur une ordonnance, du vocabulaire technique, un sigle.
- Corriger l’orthographe et la grammaire d’un texte, sans en changer le style.
- Donner un coup de main à la maison : une idée de repas avec ce qu’il reste dans le frigo, une liste de courses, un petit planning.
Au travail :
- Écrire ou reformuler un mail : une relance, une réponse, une prise de contact.
- Transformer des notes en vrac en compte-rendu propre et structuré.
- Mettre des informations en forme : un tableau, une liste à puces, un classement.
- Résumer une réunion, un document, un long fil de discussion.
Pour tout ce genre de demandes, le petit modèle de chaque assistant (Claude, Gemini, Mistral…) renvoie un résultat utilisable tel quel, qu’on serait bien en peine de distinguer de celui du gros modèle. Sauf qu’il répond plus vite et consomme une fraction de l’énergie.
Vous aurez noté que je cite Mistral aux côtés des géants américains. C’est volontaire. Les fournisseurs d’outre-Atlantique communiquent beaucoup plus, sont bien plus présents dans nos usages et ont une longueur d’avance en notoriété. Mais on peut quand même être fiers d’avoir une licorne française, Mistral AI, qui maintient un acteur européen dans la course : ses modèles sont conçus en France et l’entreprise propose un hébergement des données en Europe. Au-delà de la performance brute, garder un champion européen, c’est aussi une question d’indépendance : ne pas dépendre uniquement d’acteurs étrangers pour une technologie qui s’installe partout. Ça méritait d’être dit. Et si vous voulez l’essayer, c’est par ici : chat.mistral.ai.
Et quand le gros modèle vaut-il le coup ?#
Soyons honnêtes : il y a de vrais cas. Dès qu’il faut un raisonnement à plusieurs étapes (un calcul un peu tordu, une planification serrée avec des contraintes qui s’entrechoquent), une analyse fine et nuancée (peser le pour et le contre d’une décision importante), du code compliqué ou un sujet très pointu, la grosse machine fait la différence, et là, ça vaut le coup.
Le bon réflexe n’est donc pas de bannir le gros modèle, mais d’inverser l’ordre des choses : commencer par le petit, et ne monter en gamme que si le résultat coince. Vous serez surpris de voir à quel point ça arrive rarement.
Vos gestes concrets (le cœur du sujet)#
Si vous ne devez retenir qu’une chose, c’est ce paragraphe. Trois gestes, zéro sacrifice.
1. Ouvrez le sélecteur de modèle. C’est LE geste. Dans la plupart des applications, un menu vous laisse choisir le modèle. Prenez le léger par défaut, et ne montez en gamme que si la réponse ne vous satisfait pas. C’est exactement l’inverse du réflexe habituel. Seule exception notable parmi les grands : sur ChatGPT, ce choix est réservé aux offres payantes ; en version gratuite, le modèle vous est imposé automatiquement, sans que vous puissiez choisir.
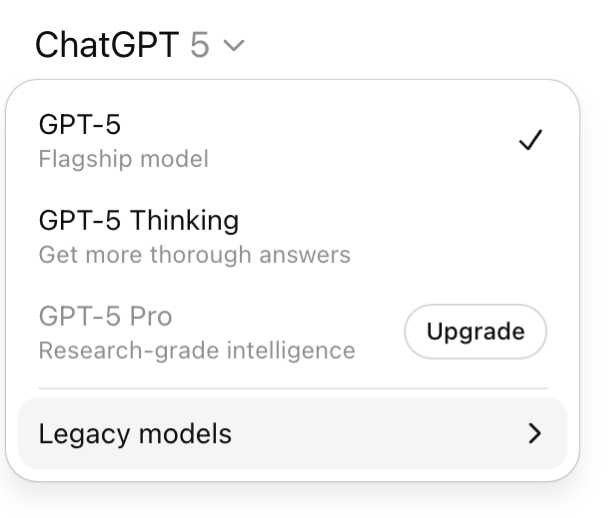
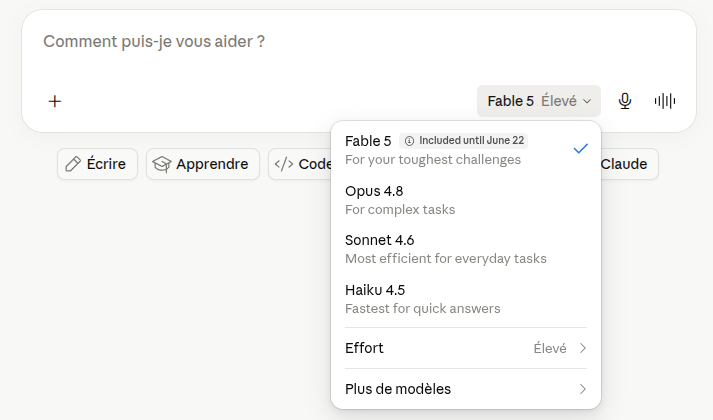
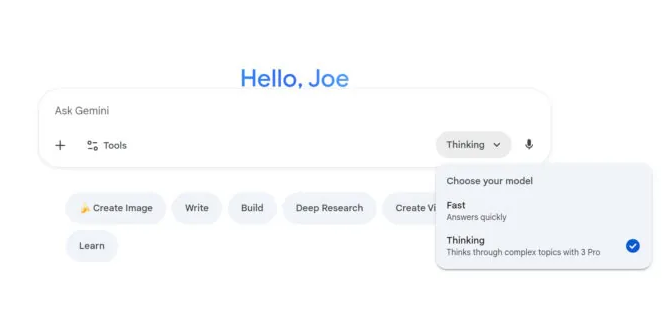
2. Désactivez le mode raisonnement quand c’est inutile. Souvenez-vous : 30 à 700 fois plus d’énergie. Gardez-le pour les vrais casse-tête (un calcul, une décision complexe). Pour une recette ou un mail, coupez-le.
3. Écrivez des questions claires. Chaque aller-retour est une requête de plus. Une question précise, avec le contexte utile dès le départ (« fais-moi un mail court, ton pro, pour relancer un client »), vous évite trois reformulations. C’est plus sobre et ça vous fait gagner du temps.
La règle à retenir tient en une phrase : pour la grande majorité de vos usages, le petit modèle suffit. Commencez petit, montez en gamme seulement si besoin.
La vraie limite : on avance à l’aveugle#
Il faut quand même pointer ce qui cloche, et ça ne dépend pas de vous : les fournisseurs d’IA sont très discrets sur la consommation réelle de leurs modèles. On a une étiquette énergie sur les frigos, les lave-linge, les ampoules, mais rien d’équivalent, ou presque, sur les assistants IA. Impossible, aujourd’hui, de savoir précisément combien consomme telle réponse de tel modèle. C’est d’ailleurs pour ça que vous ne trouverez dans cet article aucun chiffre de consommation modèle par modèle : personne ne publie de données fiables à ce niveau, et je préfère m’en tenir à des ordres de grandeur sérieux plutôt que d’inventer des chiffres précis qui auraient l’air rassurants.
Pour mémoire, l’Agence internationale de l’énergie estime que les centres de données représentaient environ 1,5 % de l’électricité mondiale en 2024, une part qui pourrait à peu près doubler d’ici 2030 sous l’effet de l’IA. C’est un sujet de société qui dépasse largement votre menu déroulant, mais votre menu déroulant, lui, est à portée de clic.
Et puis il y a une suite possible, plus radicale et plus rigolote : faire tourner un petit modèle chez soi, sur sa propre machine, sans passer par le moindre centre de données. C’est tout à fait à la portée d’un homelab, et ça tombe bien, c’est précisément le genre de chose que je bricole dans ma série homelab. On en reparlera.
En attendant, le prochain geste est simple. La prochaine fois que vous ouvrez votre assistant IA, jetez un œil à ce petit menu en haut de l’écran. Et posez-vous juste cette question :
Kentrow
Sources#
- UNESCO & University College London (2025), Smarter, smaller, stronger: Resource-efficient generative AI, unesco.org : ~0,34 Wh par requête, plus de 310 GWh/an, jusqu’à 90 % d’économie d’énergie avec des modèles compacts.
- Charles Duprat, ICOM’Provence (mars 2026), analyse de la chaîne complète requête IA vs recherche web mobile, relayée par Korben et le Journal du Net : rapport ~5,4× en faveur de l’IA, modes raisonnement 30 à 700× plus énergivores.
- Agence internationale de l’énergie (AIE / IEA), Energy and AI (2025), iea.org : les data centers ≈ 1,5 % de l’électricité mondiale en 2024 (415 TWh), avec un doublement possible d’ici 2030.
- Paradoxe de Jevons, Wikipédia : quand l’efficacité d’usage d’une ressource augmente, la consommation totale tend à augmenter plutôt qu’à diminuer.



